Intel® VTune™ Profiler¶
简介¶
Intel® VTune™ Profiler针对HPC、云、物联网、媒体、存储等优化应用程序性能、系统性能和系统配置。
CPU、GPU和FPGA:调整整个应用程序的性能,而不仅仅是加速部分。
多语言:Profile SYCL*、C、C++、C#、Fortran、OpenCL™代码、Python*、Google Go*编程语言、Java*。NET、Assembly或任何语言组合。
系统或应用程序:获取长时间的粗粒度系统数据或映射到源代码的详细结果。
电源:优化性能,同时避免与电源和热相关的节流。
安装和使用¶
安装¶
作为oneapi工具包的组件下载安装
Intel® oneAPI Base Toolkit 中包含“Intel VTune Profiler”,这是一组核心工具和库,用于跨不同体系结构开发高性能、以数据为中心的应用程序。集群中已经安装了oneapi,请查看相关 说明。
单独安装
可以单独下载“Intel VTune Profiler ”。您可以从英特尔下载二进制文件,也可以选择您喜欢的存储库。 下载地址
更详细的安装方式请看这里。
使用方法¶
图形化¶
intel vtune Profiler作为oneapi工具的一部分,可以直接使用集群中的oneapi。使用方法如下:
$ module load oneapi/2024.1.0 #根据集群中不同的oneapi挂载相应模块。
$ vtune-gui #启动vtune profiler图形界面
打开后出现此欢迎界面:
A.使用示例
可以看到,出现的欢迎页左边有个Project Navigator,默认情况下,sample(matrix)项目应该已经在Project Navigator中打开。如果是,则无需采取进一步行动。
如果示例(矩阵)项目在“Project Navigator”中不可用,请手动打开项目:
1)单击最左侧“菜单”按钮,然后选择Open > Project。。。以打开现有项目。
2)浏览到本地计算机上的矩阵项目,然后单击“open”。
默认情况下,它位于以下目录中:$HOME/intel/vtune/projects/sample(matrix)
这时候“VTune Profiler”在“Project Navigator”中打开matrix项目。
双击“Project Navigator”中sample(matrix)下方的列表可查看系统自带的运行结果,比如“r000hs”:
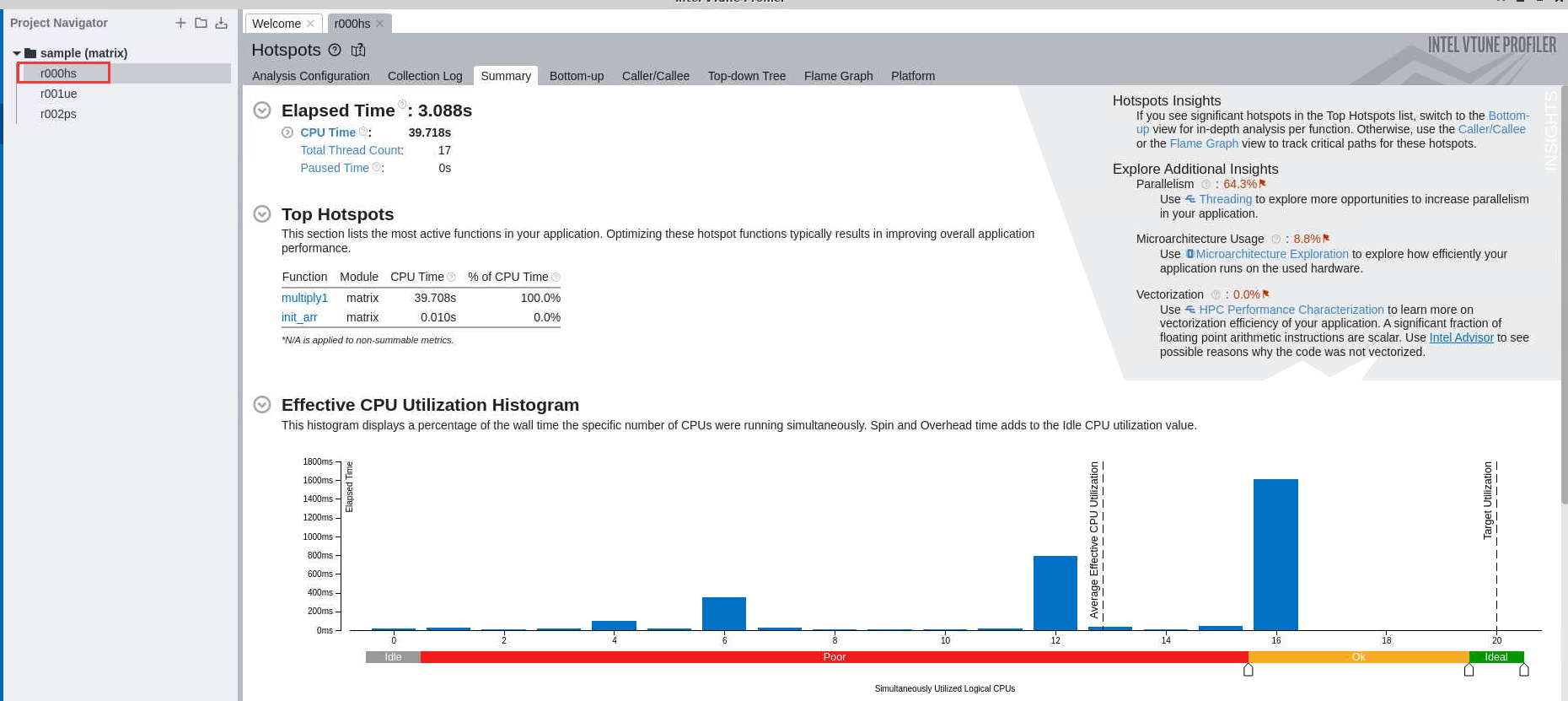
也可以在本机上重新分析,右键“Project Navigator”中sample(matrix),出现Configure Analysis界面,点击箭头指示的启动按钮,可进行Performance Snapshot性能分析:
运行完毕后会出现运行结果:
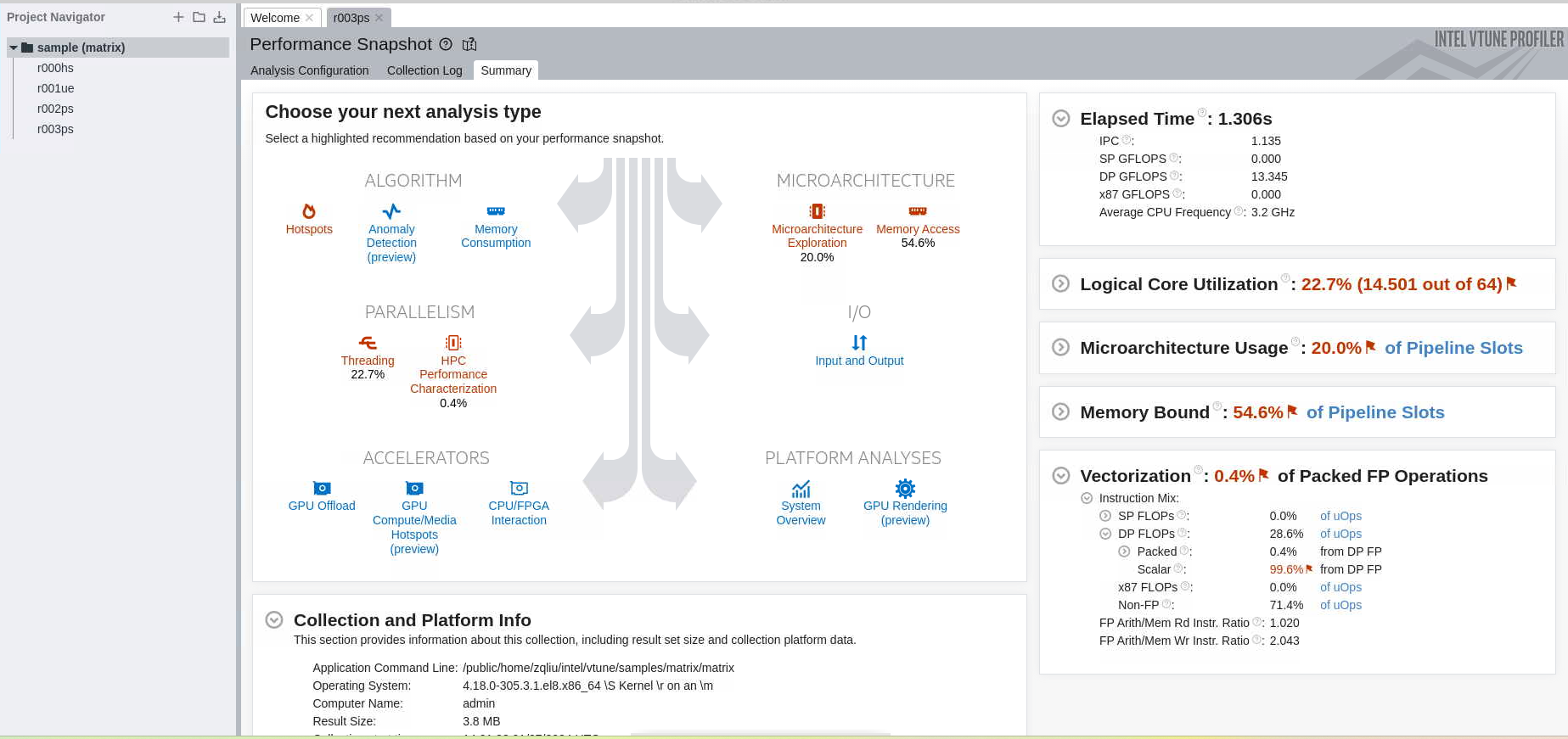
此部分更多信息请查看 Performance Analysis Tutorial for Linux* OS
官方网站还提供了其他的例子:
B.新建项目
如何分析自己的项目呢?
点击欢迎界面中的New Project:
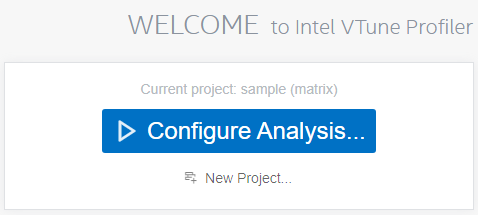
然后在出现的界面中定义设定项目名称和位置:
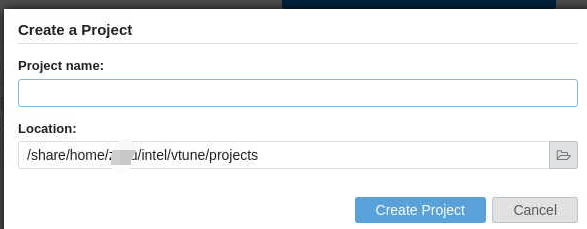
出现Configure Analysis界面:
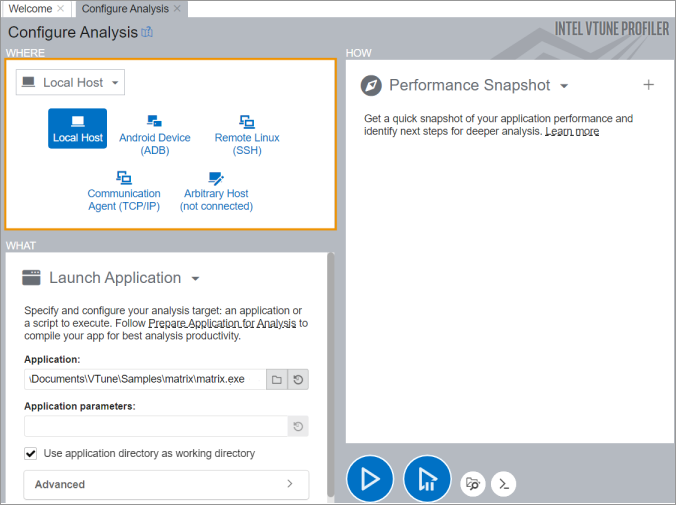
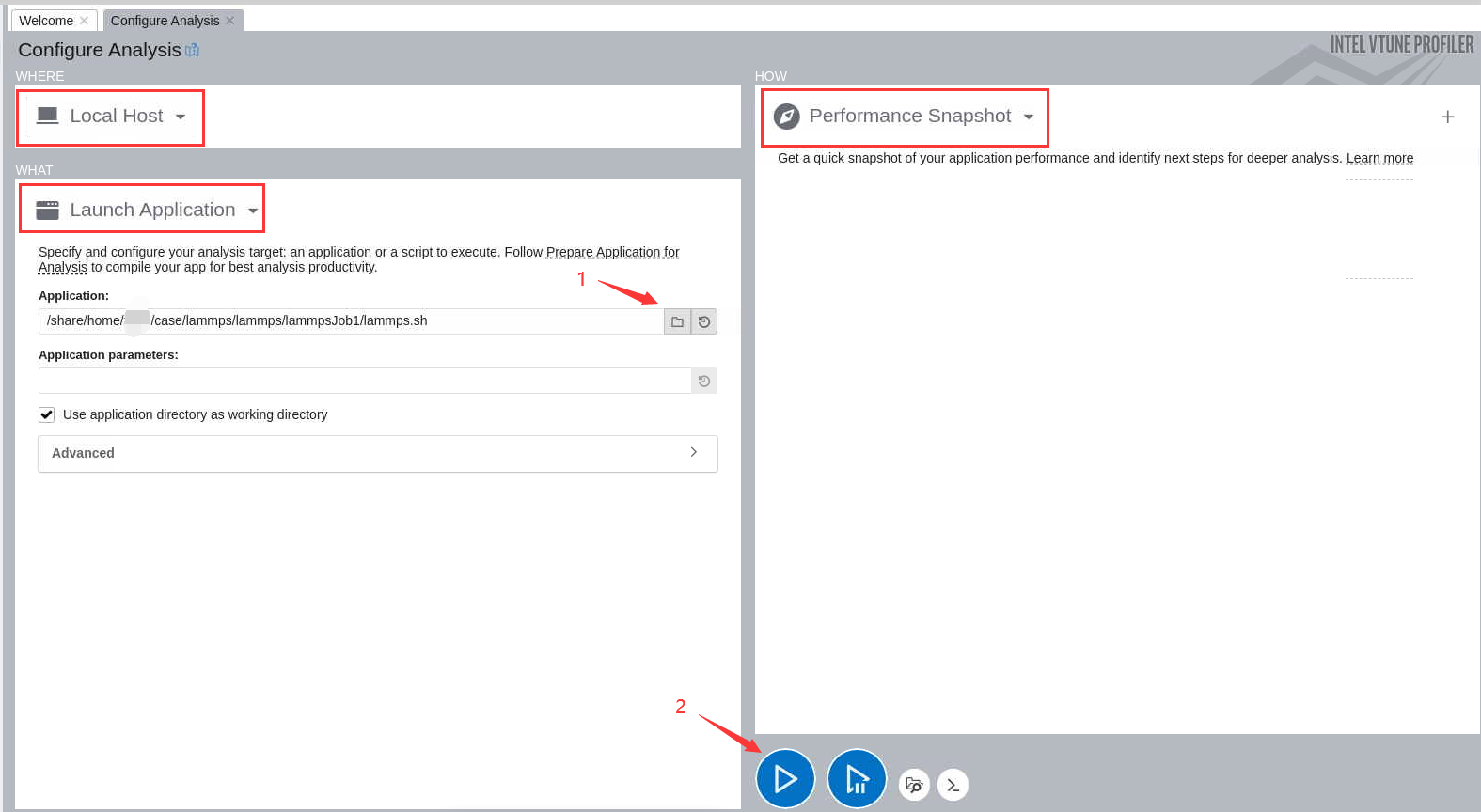
界面中有三个选项:where,what,how(有关这三个选项更详细信息请查看本栏目创建项目页面)。
选择如下选项,然后点击2的启动按钮进行性能快照分析。
命令行¶
Intel® VTune™ Profiler提供一个名为VTune工具的命令行界面。
vtune命令语法:vtune <-action> [-action-option] [-global-option] [[--] <target> [target-options]]
要查看具体选项,可使用如下命令查找帮助:
$ vtune -help #Print CLI help
$ vtune -help <action> #Get help for action and all applicable action-options
$ vtune -help collect <analysis> #Get help for analysis type and all applicable knobs (analysis-specific modifiers)
#Show description and knobs for threading analysis
$ vtune -help collect threading
tips:
也可以在图形化界面中找到相应的命令,点击Configure Analysis中箭头所示位置:
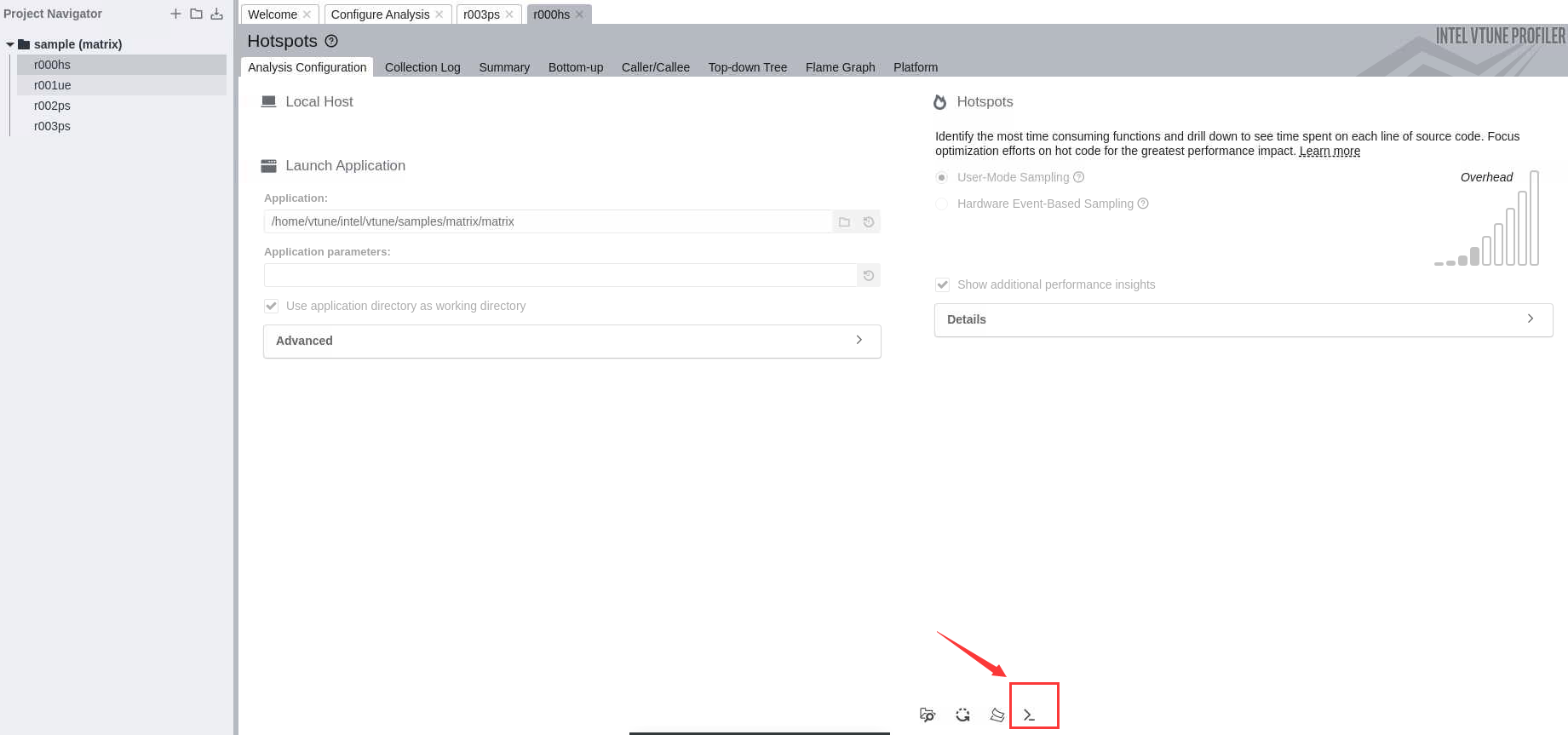
即可出现相应命令:
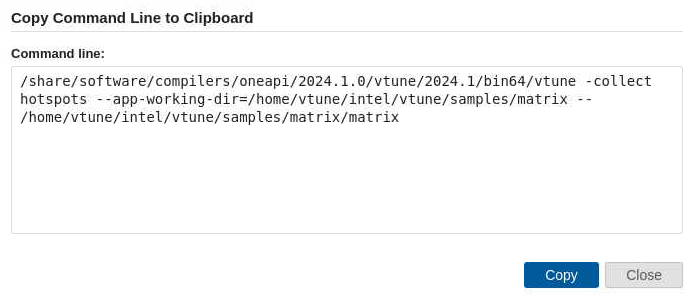
进一步了解¶
创建项目¶
点击欢迎界面中的New Project,即出现 Configure Analysis 的选项,分为如下三个部分。
WHERE: Analysis System¶
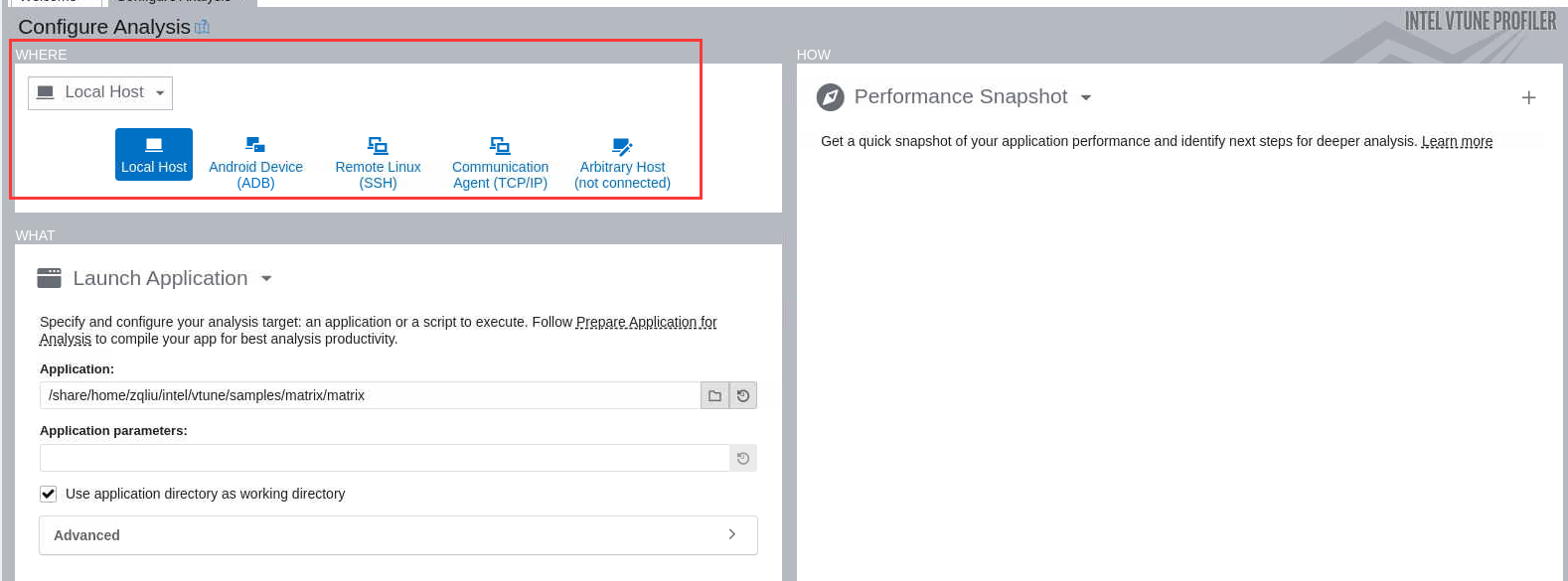
选项 |
描述 |
|---|---|
Local Host |
在本地主机系统上运行分析。不支持macos |
Remote Linux (SSH) |
在远程常规或嵌入式Linux*系统上运行分析。 “VTune Profiler”使用SSH协议连接到远程系统。 |
Android Device (ADB) |
在Android设备上运行分析。“VTune Profiler”Android Debug Bridge**(adb)连接到安卓设备。 |
Communication Agent (TCP/IP) |
使用Analysis Communication Agent评测运行实时操作系统的 嵌入式系统。 |
Arbitrary Host (not connected) |
为当前主机无法访问的平台(称为任意目标)创建命令行配置。 |
WHAT: Analysis Target¶
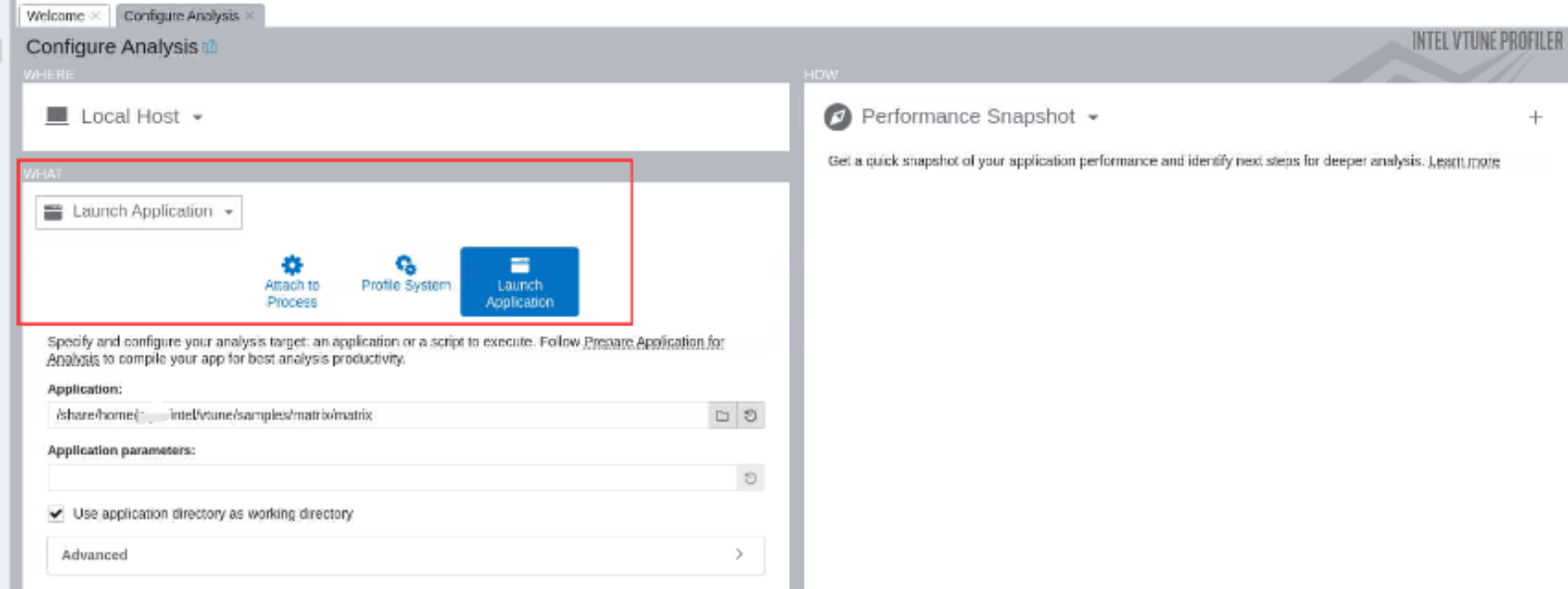
Launch Application |
启用“Launch Application”窗格,然后选择并配置要分析的应用 程序,该应用程序可以是二进制文件,也可以是脚本。 注意: Android应用程序的热点分析不支持此目标类型。请改用“Attach to Process ”或“启Launch Android Package”类型。 |
Attach to Process |
启用“附加到流程”窗格,然后选择并配置要分析的流程。 |
Profile System |
启用“Profile System ”板块并配置用于监视系统上执行的所有软件 的系统范围分析。 |
Launch Android Package |
启用Launch Android Package(启动安卓软件包)板块以指定要 分析和配置目标选项的Android*软件包的名称。 |
HOW: Analysis Types¶
“Intel® VTune™ Profiler”提供了一组预先配置的分析类型,您可以从中着手,以实现特定的性能优化目标。
创建项目时,“VTune Profiler”会打开“Configure Analysis”窗口,提示您指定要分析的内容(应用程序、进程或整个系统)(what)、计划运行分析的系统(where),然后选择需要如何运行分析(how)。
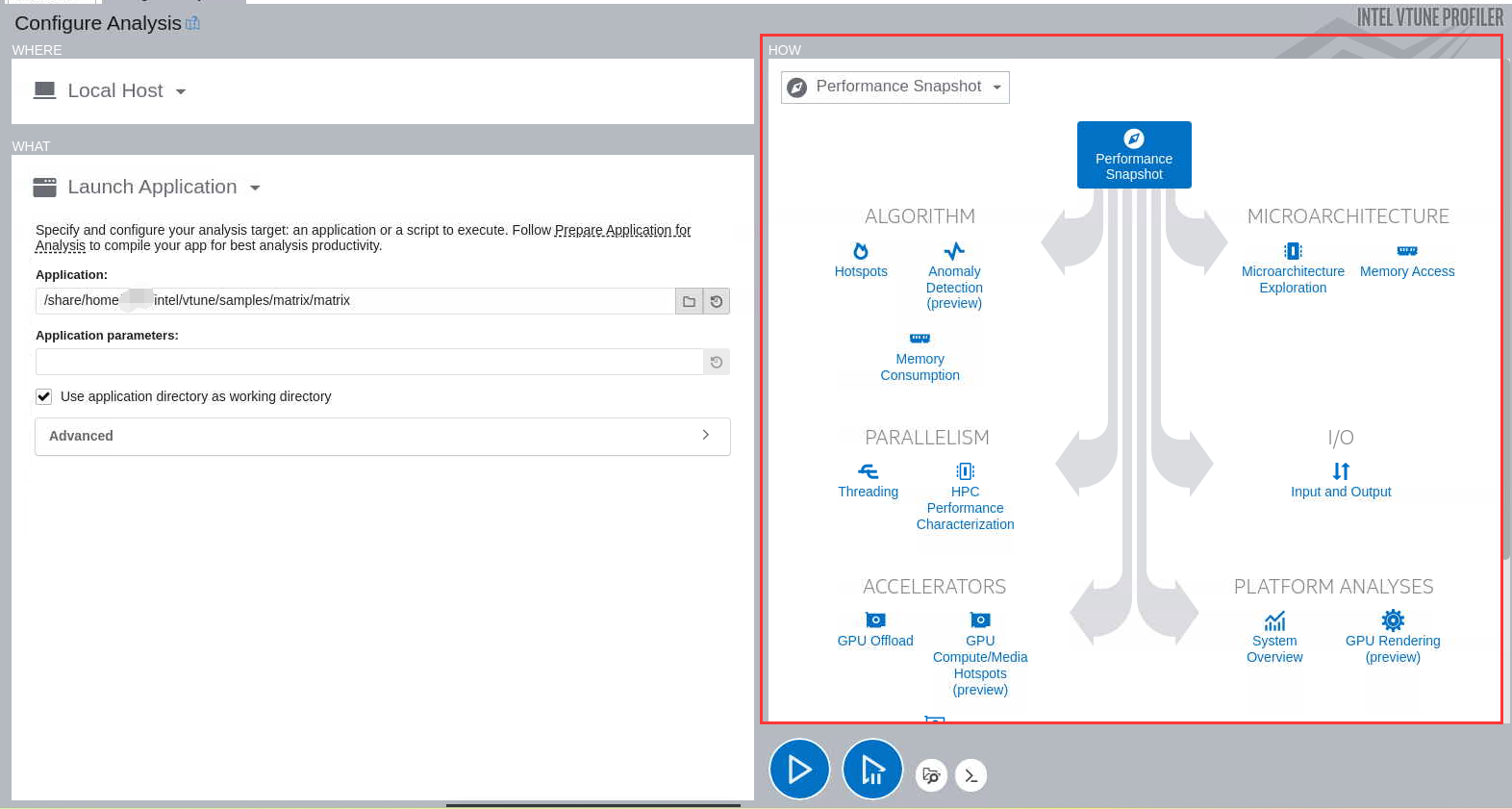
单击“如何”窗格中的标题以打开分析树。从以下组之一的分析类型中进行选择:
Analysis Group |
Analysis Types |
|---|---|
Performance Snapshot analysis |
|
Algorithm analysis |
|
Microarchitecture analysis |
|
Parallelism analysis |
|
I/O analysis |
|
Accelerators analysis |
|
Platform Analyses |
System Overview |
Performance Snapshot analysis:
使用性能快照可以概括了解影响系统上应用程序性能的问题。该分析是一个很好的起点,可以为深入关注的领域提供建议。您还可以获得关于其他分析类型的指导,以便下一步考虑运行。
Algorithm analysis:
使用Hotspots分析类型来调查调用路径,并找出代码花费最多时间的位置。确定调整算法的机会。请参阅查找热点教程:Linux|Windows。
使用异常检测(预览)来识别类似代码循环迭代的频繁重复间隔中的性能异常。以微秒级别执行细粒度分析。
内存消耗最适合分析应用程序、其不同内存对象及其分配堆栈的内存消耗。此分析仅支持Linux目标。
Microarchitecture analysis:
微体系结构探索(以前称为通用探索)最适合识别CPU管道阶段(前端、后端等)和造成硬件瓶颈的硬件单元。
内存访问最适合内存绑定应用程序,通过查看CPU缓存和主内存使用情况(包括可能的NUMA问题)来确定内存层次结构的哪个级别影响您的性能。
Parallelism analysis并行性分析:
线程化最适合于可视化可用核心上的线程并行性,查找低并发性的原因,并识别代码中的串行瓶颈。
使用HPC性能表征来了解计算密集型应用程序是如何使用CPU、内存和浮点单元(FPU)资源的。请参见分析OpenMP*和MPI应用程序教程:Linux。
I/O分析:
输入和输出分析监控IO子系统、CPU和处理器总线的利用率。
Accelerators analysis加速器分析:
GPU卸载(预览)针对使用图形处理单元(GPU)进行渲染、视频处理和计算的应用程序。它可以帮助您确定应用程序是绑定CPU还是绑定GPU。
GPU计算/媒体热点(预览)针对GPU绑定的应用程序,有助于分析每个代码行的GPU内核执行情况,并识别由内存延迟或低效内核算法引起的性能问题。
CPU/FPGA交互分析探索每个FPGA加速器的FPGA利用率,并确定最耗时的FPGA计算任务。
Platform Analyses平台分析:
系统概述是一种基于无人驾驶事件的采样分析,用于监测目标系统的一般行为,并确定限制性能的平台级因素。
VTune Profiler-Platform Profiler: :
使用“VTune Profiler-Platform Profiler”可以获得系统行为的整体视图。然后,您可以在长时间满负荷运行的已部署系统上执行系统特征化。
使用“VTune Profiler-Platform Profiler”,您可以深入了解以下方面:
平台配置
利用
表演
与计算、内存、存储、IO和互连相关的不平衡
备注
PREVIEW FEATURE可能会出现在未来的生产版本中,也可能不会出现。它可供您使用,希望您能对其有用性提供反馈,并帮助确定其未来。使用PREVIEW FEATURE收集的数据不能保证与未来版本向后兼容。
高级用户可以使用“VTune Profiler”提供的数据采集器创建自定义分析,也可以将“VTune Profiler”的采集器与另一个自定义采集器结合使用。
设置分析目标¶
为“Intel® VTune™ Profiler”性能分析创建项目时,必须设定要评测的内容—你的分析目标analysis target,可以是可执行 文件 、 进程 或整个 系统 。
在开始分析之前,请确保您的目标和系统已正确编译/配置,以便进行性能分析。
“VTune档案器”支持可以在以下环境中运行的分析目标:
Development Environment Integration |
|
Target Platform |
|
Programming Language |
|
Programming Model |
|
Virtual Environment |
|
Containers |
LXC*, Docker*, Mesos* |
Linux* Targets¶
使用“Intel® VTune™ Profiler”在本地和远程Linux*目标系统上进行性能分析。
要分析Linux目标,请执行以下操作:
1.准备您的目标应用程序进行分析:
通过安装适用于您的系统版本的调试信息包,可以下载系统内核的调试信息。
在编译代码时,使用-g选项可以下载应用程序二进制文件的调试信息。请考虑使用建议的编译器设置,使性能分析更加有效。
在发布模式下构建目标。
创建一个基线,用于比较调整后的性能改进。
例如,您对代码进行检测,以确定压缩某个文件所需的时间。您的原始目标代码经过扩充以提供这些定时数据,可作为您的性能基线。每次修改目标时,将优化目标的性能指标与基线进行比较,以验证性能是否有所改善。
2.准备您的目标系统进行分析:
如果需要,构建并安装采样驱动程序。
备注
如果在安装过程中没有构建和设置驱动程序(例如,缺少特权、缺少内核开发RPM等),“VTune Profiler”会提供一条错误消息,并基于Linux Perf*工具功能启用无人驾驶采样数据采集,该功能的分析选项范围有限。 在Ubuntu*系统上,如果ptrace()系统调用应用程序的范围有限,“VTune Profiler”可能无法收集“热点和线程”分析数据。
要解决一个会话的此问题,请使用以下命令将kernel.yama.ptrace_scopesysctl选项的值设置为0:
sysctl-w kernel.yama.ptrace_scope=0
要使此更改永久化,请参阅相应的疑难解答主题。
对于远程分析,请根据分析使用模式配置SSH连接并设置远程Linux系统。
3.创建“VTune Profiler”项目,然后运行您选择的性能分析。
为Linux*目标构建和安装采样驱动程序¶
远程Linux目标系统的先决条件:您必须具有目标系统的root访问权限。
所有Linux系统的先决条件:采样驱动程序源。您可以在“VTune Profiler”安装的<install_dir>/sepdk文件夹中找到本地系统的采样驱动程序源。对于远程目标,请在安装的<install_dir>/target文件夹中找到所需系统的目标软件包,将该软件包复制到目标系统,提取并构建驱动程序。
检查采样驱动程序的安装
验证采样驱动程序是否正确安装在主机Linux系统上:
检查是否安装了采样驱动程序:
$cd<install-dir>/sepdk/src
$ ./insmod sep-q
这提供了有关当前是否加载了驱动程序的信息,如果加载了,则提供了驱动程序设备上的组所有权和文件权限的信息。
检查组权限。
如果已加载驱动程序,但您不是查询输出中列出的组的成员,请请求系统管理员将您添加到组中。默认情况下,驱动程序访问组为vtune。要检查您属于哪些组,请在命令行中键入组。只有当权限不是666时,才需要这样做。
备注
如果没有正在进行的收集,则没有加载驱动程序的执行时间开销,也没有内存使用的开销。您可以让系统模块在引导时自动加载(例如,通过默认使用的安装引导脚本)。除非“VTune档案器”正在收集数据,否则不会对系统性能产生延迟影响。
进行分析¶
创建项目,设定分析目标后,就可以运行第一次分析了。
Performance Snapshot性能快照
单击欢迎页面上的配置分析。默认情况下,此操作会打开性能快照分析类型。这是一个很好的起点,可以概括了解影响应用程序的潜在性能问题。快照视图包括您接下来应该考虑的其他分析类型的建议。
Analysis Groups分析组
正如前文所述,单击包含分析类型名称的分析标题的任意位置。这将打开分析树,您可以在其中看到分组为多个类别的其他分析类型。请参见分析类型以获取这些预定义选项的概述。
高级用户可以创建显示在分析树底部的自定义分析类型。
分析类型的方面
您可以使用图形界面(vtune-gui)或从命令行界面(vtune)运行分析类型。
“VTune Profiler”中的所有分析类型都基于以下数据采集类型之一:
User-mode sampling and tracing collection用户模式采样和跟踪采集
Hardware event-based sampling collection基于硬件事件的采样采集(driver-based或者driverless mode),可选择使用堆栈采集进行扩展
每种分析类型都提供了一组性能指标,帮助您解决代码中的问题并了解如何优化代码。
数据采集类型¶
User-Mode Sampling and Tracing Collection 用户模式采样和跟踪采集
分析应用程序执行情况时,“Intel® VTune™ Profiler”会获取应用程序如何利用系统中处理器的快照。如果线程已准备好执行或正在执行(而不是阻塞), 则认为它在特定时刻处于活动状态。当前正在运行的线程数的快照提示应用程序的并行度以及该应用程序如何利用处理器资源。 “VTune Profiler”将利用率分为以下几个范围:空闲、较差、正常和理想。
用户模式采样和跟踪收集器中断进程,收集所有活动指令地址的值,并为每个样本捕获调用序列。采样的指令指针及其调用序列(堆栈)存储在数据收集文件中。 通过调用序列统计收集的IP样本,查看器可以显示调用图或/和最耗时的路径。使用这些数据来了解统计上重要的代码部分的控制流。
在Linux*上,用户模式采样和跟踪采集器将一个代理库嵌入到已分析的应用程序中。代理为应用程序中的每个线程设置操作系统计时器。 计时器到期后,应用程序将接收由收集器处理的SIGPROF或另一个运行时信号。
当采样使用10ms的默认间隔时,用户模式采样和跟踪采集器的平均开销约为5%。
“VTune Profiler”使用用户模式采样和跟踪采集器采集以下分析类型的数据:
Hotspots
Threading
Memory Consumption
您还可以基于用户模式采样和跟踪集合 创建自定义分析类型。
收集堆栈数据
采集数据时,“VTune Profiler”在每个配置的时间间隔内分析的堆栈不超过一个。它每执行10毫秒线程就展开一次堆栈。但“VTune Profiler”可能会因为性能原因而决定跳过或模拟堆栈展开。 在这种情况下,在完成过程中处理收集的数据时,“VTune Profiler”会尝试在历史记录中为没有堆栈的事件找到匹配的堆栈。
这种方法减少了堆叠展开开销,但可能由于错误的匹配而提供不正确的堆叠。在这种情况下,“VTune Profiler”会在自下而上/自上而下的树中显示伪节点,标记为[猜测的帧]和[跳过的帧]。 请参阅故障排除以了解如何克服这些问题。
如果在展开堆栈时找不到系统或应用程序模块的符号文件,VTune Profiler也可能显示[未知帧]节点。有关详细信息,请参阅解析未知帧。
Hardware Event-based Sampling Collection基于硬件事件的采样采集
在基于硬件事件的采样(EBS)(也称为采样模式下的性能监视计数器(PMC)分析)过程中,“Intel® VTune™ Profiler”会使用性能监视单元(PMU)的计数器溢出功能评测应用程序。
数据收集器中断进程,并在中断时捕获被中断进程的IP。通过统计收集的活动进程的IP,查看器可以显示影响软件性能的统计上重要的代码区域。
“VTune Profiler”使用基于硬件事件的采样采集器来采集以下分析类型的数据:
Anomaly Detection
Hotspots (hardware event-based sampling mode)
Performance Snapshot
Microarchitecture Exploration
Memory Access
GPU Compute/Media Hotspots
GPU Offload
System Overview
Threading
HPC Performance Characterization
CPU/FPGA Interaction
也可以基于基于硬件事件的采样集合 创建自定义分析类型。
Performance Snapshot¶
“VTune Profiler”提供了多种分析类型,这些分析类型是为检查各种应用程序类型和性能方面而定制的。性能快照捕获了这些方面的图片,并概述了应用程序的工作情况。
如果要查看影响应用程序的问题摘要,请使用性能快照。此分析还包括其他分析类型的建议,您可以在下一步运行这些分析类型以进行更深入的调查。
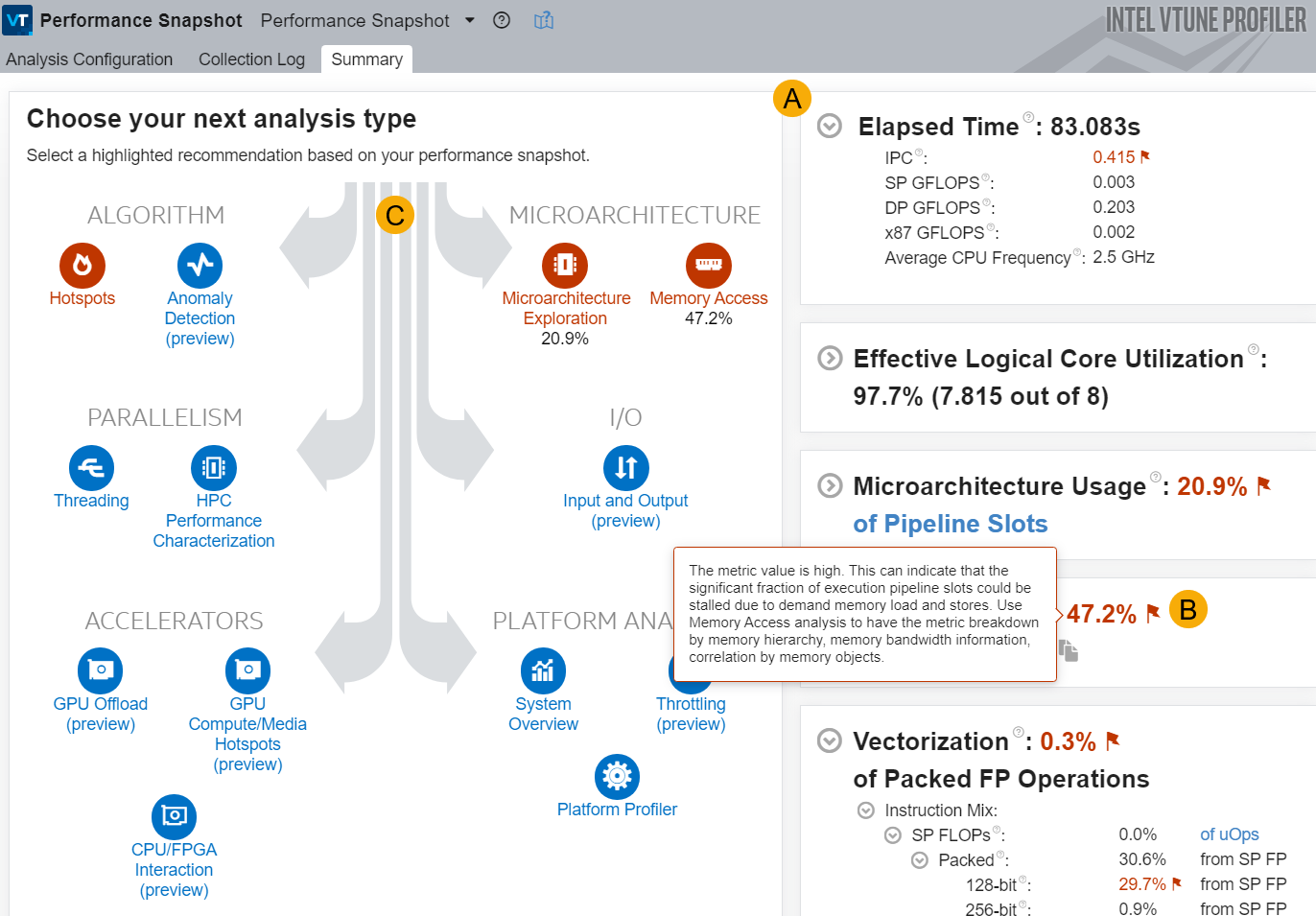
A |
展开每个指标以获取有关促成因素的详细信息。 |
B |
标记的度量表示超出可接受/正常操作范围的值。 使用工具提示了解如何改进标记的度量。 |
C |
下一步应考虑运行的其他分析指南。分析树突出显示了 这些建议 |
Algorithm Group¶
算法组中的分析针对软件调整。它们可以帮助您了解应用程序在哪里花费的时间最多。您还可以分析算法的效率。
“算法”组包括以下分析类型:
Hotspots热点关注特定目标,识别执行CPU时间最长的函数,恢复每个函数的调用树,并显示线程活动。
Anomaly Detection异常检测分析可以帮助您在类似代码循环迭代的频繁重复间隔中识别性能异常。
Memory Consumption内存消耗分析Linux*本机或Python*目标,以探索一段时间内的内存消耗(RAM),并确定在分析运行期间分配和释放的内存对象。
Microarchitecture Analysis Group¶
微体系结构分析组引入了分析类型,可以帮助您估计代码在现代硬件上运行的有效性。
微体系结构探索有助于确定影响应用程序性能的最重要硬件问题。在进行硬件级别分析时,请将此分析类型视为一个起点。
内存访问测量一组度量,以识别与内存访问相关的问题(例如,特定于NUMA体系结构)。
先决条件:
建议为基于硬件事件的采样采集类型安装采样驱动程序。对于Linux*和Android*目标,如果未安装采样驱动程序,“vtune profiler”可以在Perf*( driverless collection )上工作。请注意Linux目标系统的以下配置设置:
要启用允许测量DRAM和MCDRAM内存带宽(属于内存访问分析类型)的系统范围和非核心事件收集,请使用root或sudo将/proc/sys/kernel/perf_event_paranoid设置为0。
echo 0>/proc/sys/kernel/perf_event_paranoid
若要启用“微体系结构探索”分析类型的收集,请增加打开的文件描述符的默认限制。使用root或sudo将/etc/security/limits.conf中的默认值增加到100*<number_of_logical_CPU_cores>。
<user> hard nofile <100 * number_of_logic_CPU_cores>
<user> soft nofile <100 * number_of_logic_CPU_cores>
Parallelism Analysis Group¶
并行性分析组引入了基于计算敏感应用程序的分析类型。它们可以作为整体应用程序性能分析的起点,然后再转到更有针对性的分析类型。
计算密集型应用程序分析包括以下分析类型:
Threading线程化专注于特定的目标,显示应用程序在现有数量的逻辑CPU核心上的线程化情况,确定执行CPU时间最长的函数以及可能导致CPU使用效率低下的同步对象。
HPC Performance Characterization HPC性能表征评估浮点运算和内存效率的计算敏感或吞吐量应用程序。它可以作为了解整体应用程序性能的起点。
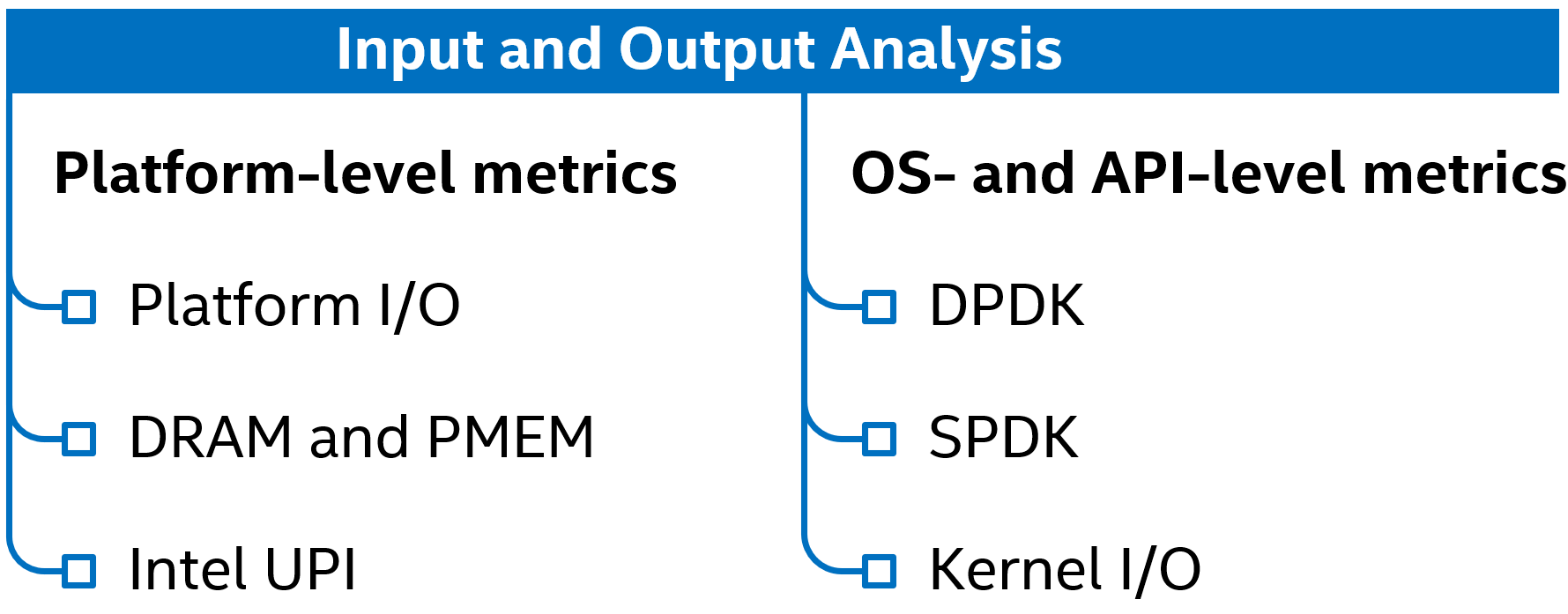
Input and Output Analysis¶
使用“ Intel® VTune™ Profiler ”的“输入与输出”分析,可以在硬件和软件两个级别查找I/O密集型应用程序中的性能瓶颈。
“ Intel® VTune™ Profiler ”的“输入与输出”分析有助于确定:
外部PCIe设备和集成加速器的平台I/O消耗:
I/O带宽消耗,包括Intel®Data Direct I/O Technology(Intel®DDIO)和Memory Mapped I/O流量。
Intel®DDIO的利用效率
内存带宽消耗。
Intel®Ultra Path Interconnect(Intel®UPI)带宽消耗。
软件数据平面利用率。
输入和输出分析具有两种主要类型的性能指标:
Platform-level metrics平台级度量——与应用程序无关的基于事件的硬件度量。
OS- and API-specific metrics特定于操作系统和API的指标-软件数据平面的性能指标-DPDK和SPDK以及Linux*内核I/O堆栈。
支持Linux*和FreeBSD*目标。
备注
全套输入和输出分析指标仅在Intel® Xeon®处理器上提供。
Accelerators Analysis Group¶
Accelerators组介绍了监控CPU、GPU、FPGA和NPU使用情况的分析类型。
使用GPU卸载分析来评测使用图形处理单元(GPU)进行渲染、视频处理和计算的应用程序。此分析类型可帮助您确定应用程序是CPU绑定还是GPU绑定。
对于GPU绑定的应用程序,请使用GPU计算/媒体热点(预览)分析类型来查看每个代码行的GPU内核执行情况。识别内存延迟或内核算法效率低下导致的性能问题。
使用CPU/FPGA交互分析来探索每个FPGA加速器的FPGA利用率,并确定最耗时的FPGA计算任务。
使用NPU探索分析(预览)来评测和优化在英特尔架构上运行的人工智能(AI)工作负载。
先决条件:
为基于硬件事件的采样采集类型安装采样驱动程序。对于Linux*和Android*目标,如果未安装采样驱动程序,“VTune Profiler”可以在Perf*( driverless collection )上工作。
要启用系统范围和非核心事件收集,请使用root或sudo将/proc/sys/kernel/perf_event_paranoid设置为0。
$echo 0>/proc/sys/kernel/perf_event_paranoid
要在Linux Ftrace子系统仅限root用户访问的系统上启用Ftrace事件的收集,请使用具有root权限的prepare-debugfs-andgpu-environment.sh脚本更改系统权限。
Platform Analysis Group¶
“平台分析”组包含用于监视系统行为和电源使用情况的“系统概述”分析。
系统概述分析是一种基于无人驾驶事件的采样分析,用于监视目标系统的一般行为。使用此分析可以确定限制性能的平台级因素,包括功耗和限制。 注意: 从Intel® VTune™ Profiler 2024.0版本开始,Platform Profiler应用程序可以单独下载。从“英特尔注册中心”访问此应用程序。
Platform Profiler应用程序将在将来的版本中停止使用。作为一种解决方法,可以考虑使用EMON数据收集器。要了解更多信息,请参阅这篇过渡 文章。
要使用2023.2或更新版本的“VTune Profiler”收集平台行为数据,请使用独立的“平台档案器”采集器。然后,您可以使用Platform Profiler服务器可视化收集的数据。有关详细信息,请参阅 平台分析 。
“Platform Profiler”分析类型在更新于2023.2的“VTune Profiler”版本中不可用。要使用“Platform Profiler”分析类型(从GUI或命令行),请切换到2023.2以前的“VTune Profiler”版本。然后,您可以按照 Platform Profiler Analysis 中描述的过程进行操作。
先决条件:
为了获得最佳结果,请为基于硬件事件的采样采集类型安装采样驱动程序。对于Linux*和Android*目标,如果未安装采样驱动程序,“VTune Profiler”可以在Perf*( driverless collection )上工作。
要启用系统范围和非核心事件收集,请使用root或sudo将/proc/sys/kernel/perf_event_paranoid设置为0。
$echo 0>/proc/sys/kernel/perf_event_paranoid
参考资料¶
本文档基于2024.2版本,有错或者有疑问请邮件至hpc@scut.edu.cn。
Contributor:mzliu